Reading a PhD dissertation on parallel computing [link PDF].
"The Cell Broadband Engine is a heterogeneous processor by itself,.."
I've been arguing that today's modern multicore CPUs are heterogeneous processors and some folks at Intel seem to agree. Processors have multiple functional units with differing capabilities, a scheduler, and wide vector units with their own Instruction Set Architecture. Each revision of Intel and AMD x86 processors seem to include a few additional instructions to power some specialized unit such as video processing or floating point.
AndyKerr insight: every modern superscalar processor is a heterogeneous platform by itself, and the extent of heterogeneity is rising.
Tuesday, December 28, 2010
Tuesday, December 14, 2010
Fall 2010 Complete
In one week, I represented GT during Micro-43, wrote a paper submitted to GPGPU-4, and completed two extensive meetings with industry sponsors. Winter 2010 will hopefully provide a much-needed reprieve.
Anyone interested in a trip to the Tennessee Valley Railroad Museum to ride #610 before her FRA boiler certificate expires? I should call up the museum to see if they plan on any steam-ups of ex Southern #630, a splendid 2-8-0 steam locomotive in the final stages of a complete restoration. Chattanooga isn't too far, but we combine trips when we can to make the most of things.
I would like to perform one sailing adventure. Things are cold, to be sure, but the winds should be stellar. If we can keep the 420 from capsizing, I'm sure we'll have one hell of a time. Robust constitutions only need apply.
A range visit is scheduled for this Friday.
Back to Christmas shopping...
Anyone interested in a trip to the Tennessee Valley Railroad Museum to ride #610 before her FRA boiler certificate expires? I should call up the museum to see if they plan on any steam-ups of ex Southern #630, a splendid 2-8-0 steam locomotive in the final stages of a complete restoration. Chattanooga isn't too far, but we combine trips when we can to make the most of things.
I would like to perform one sailing adventure. Things are cold, to be sure, but the winds should be stellar. If we can keep the 420 from capsizing, I'm sure we'll have one hell of a time. Robust constitutions only need apply.
A range visit is scheduled for this Friday.
Back to Christmas shopping...
Wednesday, November 24, 2010
Happy Thanksgiving
While preparing your Thanksgiving meal, remember the following, dear readers.

Happy Thanksgiving!
Happy Thanksgiving!
Saturday, November 20, 2010
B-Tree
Saturday morning algorithms practice: I implemented insert() and find() members std::map<> as a B-tree.
Each node in the B-tree has at most 2*t-1 keys and at most 2*t children. The best-case depth of a B-tree is log_{2*t}(N) and the worst case is log_{t}(N). During a search, O(2t) comparisons are performed per node, and O(height) nodes are visited.
For t = 3, my implementation shows the following complexity for searching:
For N = 25000, you may compare to an earlier implementation of skiplists.
Each node in the B-tree has at most 2*t-1 keys and at most 2*t children. The best-case depth of a B-tree is log_{2*t}(N) and the worst case is log_{t}(N). During a search, O(2t) comparisons are performed per node, and O(height) nodes are visited.
For t = 3, my implementation shows the following complexity for searching:
N = 1000
Average nodes visited: 4.68
log_3(N) = 6.28771 (worst)
log_6(N) = 3.85529 (best)
tree depth = 5
For N = 25000, you may compare to an earlier implementation of skiplists.
N = 25000
Average nodes visited: 7.68968
log_3(N) = 9.21766 (worst)
log_6(N) = 5.65178 (best)
depth = 8
Wednesday, November 3, 2010
LLVM Floating-point Performance Bug
I've noticed an unusual behavior of the LLVM x86 code generator that results in
nearly a 4x slow-down in floating-point throughput that I would like to report.
I've written a compute-intensive microbenchmark to approach theoretical peak
throughput of the target processor by issuing a large number of independent
floating-point multiplies. The distance between dependent instructions is at
least four instructions to match the latency of the floating-point functional
unit in my Intel Core2 Quad (Q9550 at 2.83 GHz).
The microbenchmark itself replicates the following block 512 times:
Compiling with NVCC, Ocelot, and LLVM, I can confirm the interleaved instruction
schedule with a four-instruction reuse distance. An excerpt follows:
The JIT compiler, however, seems to break the interleaving of independent instructions
and issues a long sequence of instructions with back-to-back dependencies. It is as if
all p1 = .. expressions are collected at once followed by all p2 = .. expressions and so
forth.
An actual excerpt of the generated x86 assembly follows:
Since p1, p2, p3, and p4 are all independent, this reordering is correct. This would have
the possible advantage of reducing live ranges of values. However, in this microbenchmark,
the number of live values is eight single-precision floats - well within SSE's sixteen
architectural registers.
Moreover, the pipeline latency is four cycles meaning back-to-back instructions with true
dependencies cannot issue immediately. The benchmark was intentionally written to avoid this
hazard but LLVM's code generator seems to ignore that when it schedules instructions.
When I run this benchmark on my 2.83 GHz CPU [45.3 GFLOP/s stated single-precision throughput],
I observe the following performance results:
When I rewrite the generated assembly to exhibit the same interleaving as in the LLVM IR form
observed performance increases by nearly a factor of four:
I show similar results with packed single-precision floating point instructions. The LLVM-generated
machine code is nearly 4x slower than the interleaved schedule suggested by the LLVM IR input.
It is worth noting that 39.1 GFLOP/s is approaching the theoretical limits of the processor
(stated to be 45.25 GFLOP/s single-precision).
nearly a 4x slow-down in floating-point throughput that I would like to report.
I've written a compute-intensive microbenchmark to approach theoretical peak
throughput of the target processor by issuing a large number of independent
floating-point multiplies. The distance between dependent instructions is at
least four instructions to match the latency of the floating-point functional
unit in my Intel Core2 Quad (Q9550 at 2.83 GHz).
The microbenchmark itself replicates the following block 512 times:
.
.
{
p1 = p1 * a;
p2 = p2 * b;
p3 = p3 * c;
p4 = p4 * d;
}
.
.
Compiling with NVCC, Ocelot, and LLVM, I can confirm the interleaved instruction
schedule with a four-instruction reuse distance. An excerpt follows:
.
.
%r1500 = fmul float %r1496, %r24 ; compute %1500
%r1501 = fmul float %r1497, %r23
%r1502 = fmul float %r1498, %r22
%r1503 = fmul float %r1499, %r21
%r1504 = fmul float %r1500, %r24 ; first use of %1500
%r1505 = fmul float %r1501, %r23
%r1506 = fmul float %r1502, %r22
%r1507 = fmul float %r1503, %r21
%r1508 = fmul float %r1504, %r24 ; first use of %1504
.
.
The JIT compiler, however, seems to break the interleaving of independent instructions
and issues a long sequence of instructions with back-to-back dependencies. It is as if
all p1 = .. expressions are collected at once followed by all p2 = .. expressions and so
forth.
p1 = p1 * a
p1 = p1 * a
.
.
p2 = p2 * b
p2 = p2 * b
.
.
p3 = p3 * c
p3 = p3 * c
.
.
An actual excerpt of the generated x86 assembly follows:
mulss %xmm8, %xmm10
mulss %xmm8, %xmm10
.
. repeated 512 times
.
mulss %xmm7, %xmm9
mulss %xmm7, %xmm9
.
. repeated 512 times
.
mulss %xmm6, %xmm3
mulss %xmm6, %xmm3
.
. repeated 512 times
.
Since p1, p2, p3, and p4 are all independent, this reordering is correct. This would have
the possible advantage of reducing live ranges of values. However, in this microbenchmark,
the number of live values is eight single-precision floats - well within SSE's sixteen
architectural registers.
Moreover, the pipeline latency is four cycles meaning back-to-back instructions with true
dependencies cannot issue immediately. The benchmark was intentionally written to avoid this
hazard but LLVM's code generator seems to ignore that when it schedules instructions.
When I run this benchmark on my 2.83 GHz CPU [45.3 GFLOP/s stated single-precision throughput],
I observe the following performance results:
1 threads 0.648891 GFLOP/s
2 threads 1.489049 GFLOP/s
3 threads 2.209838 GFLOP/s
4 threads 2.940443 GFLOP/s
When I rewrite the generated assembly to exhibit the same interleaving as in the LLVM IR form
.
.
mulss %xmm8, %xmm10
mulss %xmm7, %xmm9
mulss %xmm6, %xmm3
mulss %xmm5, %xmm11
mulss %xmm8, %xmm10
mulss %xmm7, %xmm9
mulss %xmm6, %xmm3
mulss %xmm5, %xmm11
mulss %xmm8, %xmm10
mulss %xmm7, %xmm9
.
.
observed performance increases by nearly a factor of four:
1 threads 2.067118 GFLOP/s
2 threads 5.569419 GFLOP/s
3 threads 8.285519 GFLOP/s
4 threads 10.81742 GFLOP/s
I show similar results with packed single-precision floating point instructions. The LLVM-generated
machine code is nearly 4x slower than the interleaved schedule suggested by the LLVM IR input.
Vectorized - No instruction interleaving - back-to-back dependencies
1 threads 1.540621 GFLOP/s
2 threads 5.900833 GFLOP/s
3 threads 8.755953 GFLOP/s
4 threads 11.257122 GFLOP/s
Vectorized - Interleaved - stride-4 reuse distance
1 threads 3.157255 GFLOP/s
2 threads 22.104369 GFLOP/s
3 threads 32.300111 GFLOP/s
4 threads 39.112162 GFLOP/s
It is worth noting that 39.1 GFLOP/s is approaching the theoretical limits of the processor
(stated to be 45.25 GFLOP/s single-precision).
Wednesday, September 29, 2010
Skiplists
Skiplists are probabilistic data structures with many of the same properties as balanced binary search trees. They are analogous to express and local passenger trains and have O(log N) insert and search complexities.
I implemented a skiplist container class in C++ to have the same semantics as STL's std::map<>. Here are some results for insertion of unique integers in random order:
Another neat property is there isn't an expensive re-balancing operation as seen in red-black and AVL trees. The insert() and delete() operations simply need to update at most log_2(N) pointers. Haven't looked at actual performance of my implementation but I thought it was an interesting exercise.
Here is an example skiplist after 11 inserts (after the jump).
I implemented a skiplist container class in C++ to have the same semantics as STL's std::map<>. Here are some results for insertion of unique integers in random order:
iteration and search tests pass.
N = 25000
avg insert: 13.1927
log_2(N): 14.6096
N = 25000
avg search: 14.503
log_2(N): 14.6096
Another neat property is there isn't an expensive re-balancing operation as seen in red-black and AVL trees. The insert() and delete() operations simply need to update at most log_2(N) pointers. Haven't looked at actual performance of my implementation but I thought it was an interesting exercise.
Here is an example skiplist after 11 inserts (after the jump).
Monday, August 16, 2010
Ascent of Mount Rainier
On August 14, I set out with three companion to summit Mount Rainier. At 9:15 am yesterday, August 15, we reached the summit crater.
The climb was well-documented with a digital camera, but here are some snapshots I took with my iPhone.

Mount Rainier seen from Muir Snowfield

Summit crater of Mount Rainier

Me, Ryan, and Tim (left to right) on Columbia Crest looking northwest toward Seattle.

Me on Columbia Crest with Mount Adams in background
Comprehensive post to follow.
The climb was well-documented with a digital camera, but here are some snapshots I took with my iPhone.

Mount Rainier seen from Muir Snowfield

Summit crater of Mount Rainier

Me, Ryan, and Tim (left to right) on Columbia Crest looking northwest toward Seattle.

Me on Columbia Crest with Mount Adams in background
Comprehensive post to follow.
Friday, August 13, 2010
Mount Rainier Weather Forecast
I've been refreshing this page continuously for the past few days. If the forecast is correct, the summit should be warm and relatively calm. I'll have my four thermal layers nevertheless, but I feel the need to post the current forecast (below the break).

Mount Rainier, August 22, 2009
Mount Rainier, August 22, 2009
Thursday, August 12, 2010
Mount Rainier Climbing Information
Here are some Mount Rainier climbing resources if you're interested.
Climbing information
Climbing routes (look for Paradise Routes - this is the best topographic map of the route to summit)
Route information
Equipment checklist
Weather forecast
Climbing information
Climbing routes (look for Paradise Routes - this is the best topographic map of the route to summit)
Route information
Equipment checklist
Weather forecast
To Climb Mount Rainier
The stars have aligned such that I might be a part of a three or four person rope team to attempt a summit of Mount Rainier on the weekend of August 13 - August 15. If all goes according to plan, we will reach Mount Rainier's 14,400 ft summit crater by approximately 10am Sunday morning.
A detail plan will come out of a meeting between the climbers tomorrow evening. We will follow the Disappointment Cleaver route. This is a two-day climb from the trailhead at Paradise to high camp at Camp Muir (10,100 ft) on a ridge between Cowlitz and Nisqually Glacier on Rainier's southern face. Early the next morning, we'll rope up and cross Cowlitz glacier and Ingraham flats toward Disappointment Cleaver, a rock formation dividing Emmons and Ingraham Glaciers. Once we reach the top of this formation, we'll proceed over snow up toward the crater rim, and from there to Columbia Crest (summit ridge) if weather permits.
I hope it permits.
Update:
Follow Mount Rainier's weather forecast http://www.atmos.washington.edu/data/rainier_report.html.
That appears to be ideal climbing weather.
A detail plan will come out of a meeting between the climbers tomorrow evening. We will follow the Disappointment Cleaver route. This is a two-day climb from the trailhead at Paradise to high camp at Camp Muir (10,100 ft) on a ridge between Cowlitz and Nisqually Glacier on Rainier's southern face. Early the next morning, we'll rope up and cross Cowlitz glacier and Ingraham flats toward Disappointment Cleaver, a rock formation dividing Emmons and Ingraham Glaciers. Once we reach the top of this formation, we'll proceed over snow up toward the crater rim, and from there to Columbia Crest (summit ridge) if weather permits.
I hope it permits.
Update:
Follow Mount Rainier's weather forecast http://www.atmos.washington.edu/data/rainier_report.html.
.THURSDAY...SUNNY. FREEZING LEVEL 14000 FEET.
.THURSDAY NIGHT...MOSTLY CLEAR. FREEZING LEVEL 15000 FEET.
.FRIDAY...SUNNY. FREEZING LEVEL ABOVE 15000 FEET.
.FRIDAY NIGHT...CLEAR. FREEZING LEVEL ABOVE 15000 FEET.
.SATURDAY...SUNNY. FREEZING LEVEL ABOVE 15000 FEET.
.SATURDAY NIGHT THROUGH WEDNESDAY...CLEAR NIGHTS AND SUNNY DAYS. FREEZING
LEVEL ABOVE 15000 FEET.
That appears to be ideal climbing weather.
Wednesday, July 28, 2010
Glacier Training: Prusik
The essence of human-powered ascent, by any means, is a lift followed by a rest. When climbing stairs, you lift yourself then stand while hoisting your free leg to the next tread. When climbing a rope, it's quite beneficial to have similar options. It is ideal if your legs can bear most of the lifting load, yet at any point relax while muscles regain strength.
Enter the prusik hitch.
Enter the prusik hitch.
Monday, July 26, 2010
Glacier Training on Mount Baker
The climb of Mount Adams two weeks ago was exhilarating and exhausting, but an important element of mountaineering was [thankfully] lacking: ice. Glaciers present a new set of hazards and require specialized techniques to overcome them. It behooves every mountaineer to obtain training and plenty of practice such that, in an emergency, the mountaineer can immediately swing into action and apply rescue procedures quickly and correctly. We react how we train.

I was fortunate enough to spend this weekend camping with Brooke and Ryan next to a glacier on Mount Baker. Ryan had taken a glacier class from a mountaineering guide service the previous weekend and explained to us as much of the material as we could get through. On the glacier, we put these concepts into action. Here is a list of the glacier traversal and rescue procedures we covered.
The two-day trip consisted of the following events.
On Day 1, we: drove to Mount Baker-Snoqualmie National Forest, we hiked 2.5 miles from the trailhead to the camp site crossing numerous streams carrying glacier melt water down the volcano, setup camp, discussed rope climbing fundamentals, prusiked up a tree, had camp supper, enjoyed a view of the heavily glaciated face of Mount Baker, enjoyed discussion with some other climbers camping there, and I slept in a bivouac sack+thermarest+sleeping bag.
On Day 2, we: carried gear onto the glacier, practiced traversal techniques, climbed over some ice mounds, made all sorts of anchors, setup ropes, practiced rescue techniques, practiced self-arrests, ice climbed, broke camp, hiked out, and enjoyed a nice supper at a brewery in Bellingham.
What will eventually follow is a brief description of each of the hazards and techniques we trained for. The entire two-day trip was well documented, for the sake of both posterity and so I can review material. It will take several days to coalesce photos from two cameras and write things down, but I'll try to complete at least one section before the end of the week.
Coming soon: Prusiking
I was fortunate enough to spend this weekend camping with Brooke and Ryan next to a glacier on Mount Baker. Ryan had taken a glacier class from a mountaineering guide service the previous weekend and explained to us as much of the material as we could get through. On the glacier, we put these concepts into action. Here is a list of the glacier traversal and rescue procedures we covered.
- prusiking
- glacier traversal
- crevasse identification
- anchoring in snow
- anchoring in ice
- roping up
- self-arrest
- crevasse rescue
- ice climbing
The two-day trip consisted of the following events.
On Day 1, we: drove to Mount Baker-Snoqualmie National Forest, we hiked 2.5 miles from the trailhead to the camp site crossing numerous streams carrying glacier melt water down the volcano, setup camp, discussed rope climbing fundamentals, prusiked up a tree, had camp supper, enjoyed a view of the heavily glaciated face of Mount Baker, enjoyed discussion with some other climbers camping there, and I slept in a bivouac sack+thermarest+sleeping bag.
On Day 2, we: carried gear onto the glacier, practiced traversal techniques, climbed over some ice mounds, made all sorts of anchors, setup ropes, practiced rescue techniques, practiced self-arrests, ice climbed, broke camp, hiked out, and enjoyed a nice supper at a brewery in Bellingham.
What will eventually follow is a brief description of each of the hazards and techniques we trained for. The entire two-day trip was well documented, for the sake of both posterity and so I can review material. It will take several days to coalesce photos from two cameras and write things down, but I'll try to complete at least one section before the end of the week.
Coming soon: Prusiking
Tuesday, July 20, 2010
Wednesday, July 14, 2010
Climbing Mount Adams
Mount Adams Climb Report. What follows is a somewhat meandering description of my climb of Mount Adams. I wrote most of this several days after the climb but didn't wrap it up until just now. One could conceivably annotate each paragraph with photos from the next blog post.
Mount Adams is a prominent 12,280 ft stratovolcano in southern Washington state approximately 25 miles north of the Hood River and 20 miles east of Mount St. Helens. In early July, its beautiful slopes are snow-covered and offers an 'easy' climbing route along its southern face that is free from significant mountaineering hazards - crevasses to fall into, cliffs from which rocks fall, and avalanche-prone slopes - making it a popular climb for residents of Portland and Seattle. On July 11, 2010, I accompanied my roommate Tim and his friend Rumi to the summit of Mount Adams in a single day's climb.
Mount Adams is a prominent 12,280 ft stratovolcano in southern Washington state approximately 25 miles north of the Hood River and 20 miles east of Mount St. Helens. In early July, its beautiful slopes are snow-covered and offers an 'easy' climbing route along its southern face that is free from significant mountaineering hazards - crevasses to fall into, cliffs from which rocks fall, and avalanche-prone slopes - making it a popular climb for residents of Portland and Seattle. On July 11, 2010, I accompanied my roommate Tim and his friend Rumi to the summit of Mount Adams in a single day's climb.
Tuesday, July 13, 2010
Blog Slacking
Since May, I've driven across the country, lived in Seattle for a week, visited San Francisco for a week, attended Emma's graduation ceremony, moved to Bellevue, written a whole lot of code, climbed several hills, biked all around, gone sailing, visited Illinois, and climbed Mount Adams. Shockingly, the only thing I've blogged during all of this is a simple quine I wrote in CUDA, and even then it was only to document having done it first.
I'm a slacker.
In related news, I've implemented a photo gallery for FanBolt that I also plan on installing on akerr.net. It should satisfy the purposes of this blog quite well. As there is a value cliff coinciding with ComiCon for getting the photo gallery into production, it better be working by the end of this weekend. At that point in time, I'll upload photos from each of the above adventures to get some kind of documentation to you [few, eternally optimistic] readers!
Blogger iframe test:
I'm a slacker.
In related news, I've implemented a photo gallery for FanBolt that I also plan on installing on akerr.net. It should satisfy the purposes of this blog quite well. As there is a value cliff coinciding with ComiCon for getting the photo gallery into production, it better be working by the end of this weekend. At that point in time, I'll upload photos from each of the above adventures to get some kind of documentation to you [few, eternally optimistic] readers!
Blogger iframe test:
Tuesday, June 29, 2010
First CUDA Quine
As you may know, a quine is a short program that prints its own source code using common facilities of the language. With CUDA 3.0 and Fermi's support of printf(), this isn't very difficult to do with CUDA. Here is an example, the first I've seen to run on a GPU.
$ cat quine.cu
#include <stdio.h>
__device__ const char *f="#include <stdio.h>%c__device__ const char *f=%c%s%c; __global__ void k(){ printf(f,10,34,f,34,10); } int main() { k<<< dim3(1,1),dim3(1,1)>>>(); cudaThreadExit(); return 0; }%c"; __global__ void k(){ printf(f,10,34,f,34,10); } int main() { k<<< dim3(1,1),dim3(1,1)>>>(); cudaThreadExit(); return 0; }
$ nvcc --run quine.cu -arch sm_20 > quine2.cu
$ diff quine.cu quine2.cu
$ nvcc --run quine2.cu -arch sm_20 > quine3.cu
$ diff quine.cu quine3.cu
$
Tuesday, March 30, 2010
Ocelot Overview
With 2010 being the year of the Ocelot, I've made a slight modification to the Ocelot Overview image that has found its way into so many presentations [not all of which have been mine]. See if you can spot it.

Saturday, March 6, 2010
Baker Valve Gear Simulator in Python
What started off as a compile-time project has finally yielded some results.
As some of you are aware, my interests in engineering exceed computing and from time to time take the front seat for brief periods. In this case, I've spent two weekends volunteering at the Southeastern Railway Museum shops with the hope of working on the preservation and restoration of the exquisite A&WP 290. The neat thing about steam locomotives is they're incredibly overt exhibitions of thermodynamics and mechanics. The boiler is a giant heat exchanger that sends steam to cylinders where work is performed. A mechanical linkage outside the frame transmits this power to the wheels and uses the wheel position to configure valves that admit and exhaust the working fluid.
One of the things I was interested in was a mathematical model of this linkage. This sort of modelling has applications in robotics and kinematics simulations, so it's not too bizarre of a topic for a computer engineer to dabble in. To simulate the valve gear, I constructed a set of polynomial equations modelling each rod as a constant length between two points capable of 2D motion in a plane. The collection of pin joints and rigid rods determines a finite set of possible static equilibria for the system. Enough points can be computed analytically so a numerical non-linear equation solver can compute the others.
I wrote a Python application [distributed as source] using SciPy's fsolve() to simulate the running gear. Plots generated with matplotlib provide visual output.
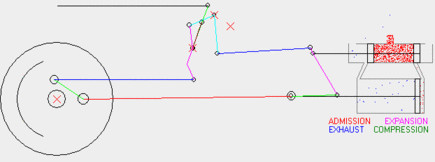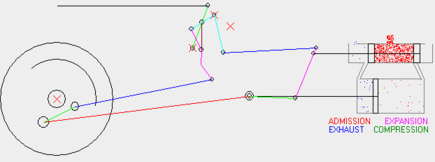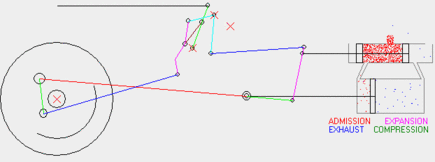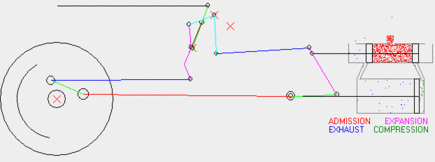
Here are some of the results. This wikipedia article explains the Baker valve gear and this animated gif shows it in operation [generated from an existing valve gear simulator which I've not yet used to validate mine]. Other valve gears are explained on this page if you're interested.
The following plot illustrates the state of the running gear for several wheel rotations. Not every part is a two-joint rod; there is a bellcrank and an eccentric crank mounted to the main crank pin. See the Wikipedia article for a better illustration.

The following plot illustrates the offsets of the crosshead and cylinder valves for two different cutoffs and two different laps. Cutoff is the angle between vertical and the valve gear's yoke. 0 degrees is effectively neutral, and +25 degrees is "well forward." Setting it to a negative angle reverses the locomotive. Lap is, in a manner of speaking, the amount of motion derived from the crosshead; the valves can move this much without actually admitting any steam. It's worth noting that lap is built into the valve gear, while cutoff is a setting that is adjusted during operation.

To achieve smooth operation, it's desirable to admit steam into the cylinder before the piston has reached front or back dead center. This "lead" is effectively a phase offset that depends on the direction of motion. The amount of lap affects the amount of lead by mixing the 90-degree offset motion of the valve gear with the crosshead via the combination lever. The following plot illustrates the displacement of the cylinder valves as zero-mean curves to enable a direct comparison of 0" and 3.5" of lap. In practice, it's easy to add a constant linear offset to the cylinder valve spindle, and this is one of the variables that must be tuned when the locomotive is overhauled.

The rod sizes and geometry used in this simulation were estimated from photographs of A&WP 290 as well as direct measurements. I didn't get every measurement I wanted, as I was taking them by hand with a tape measure that falls apart, and real locomotives are 3 dimensional and quite large. Nevertheless, this was an interesting project and I'm very gratified by the results. Maybe one day I'll build a 7.5" gauge live steamer and dust off this code for design purposes...
As some of you are aware, my interests in engineering exceed computing and from time to time take the front seat for brief periods. In this case, I've spent two weekends volunteering at the Southeastern Railway Museum shops with the hope of working on the preservation and restoration of the exquisite A&WP 290. The neat thing about steam locomotives is they're incredibly overt exhibitions of thermodynamics and mechanics. The boiler is a giant heat exchanger that sends steam to cylinders where work is performed. A mechanical linkage outside the frame transmits this power to the wheels and uses the wheel position to configure valves that admit and exhaust the working fluid.
One of the things I was interested in was a mathematical model of this linkage. This sort of modelling has applications in robotics and kinematics simulations, so it's not too bizarre of a topic for a computer engineer to dabble in. To simulate the valve gear, I constructed a set of polynomial equations modelling each rod as a constant length between two points capable of 2D motion in a plane. The collection of pin joints and rigid rods determines a finite set of possible static equilibria for the system. Enough points can be computed analytically so a numerical non-linear equation solver can compute the others.
I wrote a Python application [distributed as source] using SciPy's fsolve() to simulate the running gear. Plots generated with matplotlib provide visual output.
Here are some of the results. This wikipedia article explains the Baker valve gear and this animated gif shows it in operation [generated from an existing valve gear simulator which I've not yet used to validate mine]. Other valve gears are explained on this page if you're interested.
{kind=link}
The following plot illustrates the state of the running gear for several wheel rotations. Not every part is a two-joint rod; there is a bellcrank and an eccentric crank mounted to the main crank pin. See the Wikipedia article for a better illustration.
The following plot illustrates the offsets of the crosshead and cylinder valves for two different cutoffs and two different laps. Cutoff is the angle between vertical and the valve gear's yoke. 0 degrees is effectively neutral, and +25 degrees is "well forward." Setting it to a negative angle reverses the locomotive. Lap is, in a manner of speaking, the amount of motion derived from the crosshead; the valves can move this much without actually admitting any steam. It's worth noting that lap is built into the valve gear, while cutoff is a setting that is adjusted during operation.
To achieve smooth operation, it's desirable to admit steam into the cylinder before the piston has reached front or back dead center. This "lead" is effectively a phase offset that depends on the direction of motion. The amount of lap affects the amount of lead by mixing the 90-degree offset motion of the valve gear with the crosshead via the combination lever. The following plot illustrates the displacement of the cylinder valves as zero-mean curves to enable a direct comparison of 0" and 3.5" of lap. In practice, it's easy to add a constant linear offset to the cylinder valve spindle, and this is one of the variables that must be tuned when the locomotive is overhauled.
The rod sizes and geometry used in this simulation were estimated from photographs of A&WP 290 as well as direct measurements. I didn't get every measurement I wanted, as I was taking them by hand with a tape measure that falls apart, and real locomotives are 3 dimensional and quite large. Nevertheless, this was an interesting project and I'm very gratified by the results. Maybe one day I'll build a 7.5" gauge live steamer and dust off this code for design purposes...
Wednesday, February 17, 2010
NP
I thought of this XKCD comic last night as I was showing problems were in NP. Resurrected for your amusement.
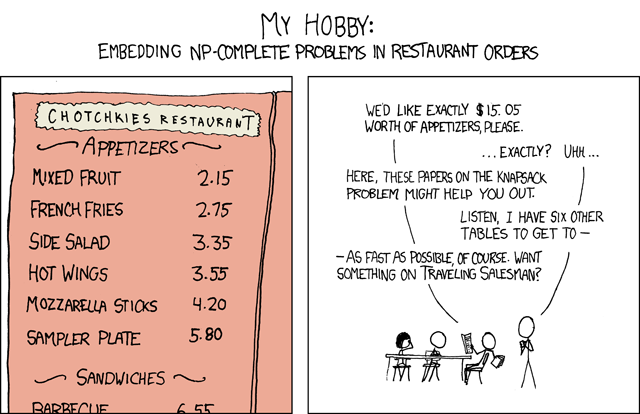
Read up on Karp's NP-Complete Problems.
Read up on Karp's NP-Complete Problems.
Monday, February 15, 2010
Upwelling Within
I have the urge to build something in ways that do not involve typing. Something mechanical with moving parts.
In potentially related news, this looked neat: Crower six-stroke diesel.
In potentially related news, this looked neat: Crower six-stroke diesel.
Sunday, February 14, 2010
Motherboard Death Throws
My desktop is back. Evidently, one [of three] PCI-Express x16 lanes is dead as is one of the memory channels. The system refuses to POST with something occupying any of the damaged connectors. This leaves two [though one inaccessible] PCI-Express x16 slots and one memory channel still viable. I can make do with this configuration for the time being.
The experience has prompted the question of what I want in a home desktop. While there was a time when GPU VSIPL development and benchmarking demanded a high-end system, now I do most work on other resources purchased by the research budget. I don't game, and I do most home development on my laptop which is typically booted into Linux. I wouldn't have a need for Windows at all except to synchronize my iPhone, though it's nice to have that kind of compatibility for special interests and the occasional foray into 3D graphics programming. That said, a low-end multicore CPU and medium-range GPU could satisfy those needs quite well.
With a medium-performance laptop dual booting Windows and Linux, do I need the desktop at all?
The strongest reason I can see for wanting one is to have a stable place for an array of harddrives to ensure reliable access to a decade or so of accumulated data. That's a task easily serviced by network-attached storage [1].
This has disturbing implications for the value of my research interests at the consumer level...
[1] BUT NOT IF IT'S MADE BY LACIE - you're better off keeping your data on floppy disks under your mattress than shoveling it into that black hole of a storage medium; it's a place where entropy goes to die; fail fail fail.
The experience has prompted the question of what I want in a home desktop. While there was a time when GPU VSIPL development and benchmarking demanded a high-end system, now I do most work on other resources purchased by the research budget. I don't game, and I do most home development on my laptop which is typically booted into Linux. I wouldn't have a need for Windows at all except to synchronize my iPhone, though it's nice to have that kind of compatibility for special interests and the occasional foray into 3D graphics programming. That said, a low-end multicore CPU and medium-range GPU could satisfy those needs quite well.
With a medium-performance laptop dual booting Windows and Linux, do I need the desktop at all?
The strongest reason I can see for wanting one is to have a stable place for an array of harddrives to ensure reliable access to a decade or so of accumulated data. That's a task easily serviced by network-attached storage [1].
This has disturbing implications for the value of my research interests at the consumer level...
[1] BUT NOT IF IT'S MADE BY LACIE - you're better off keeping your data on floppy disks under your mattress than shoveling it into that black hole of a storage medium; it's a place where entropy goes to die; fail fail fail.
Wednesday, February 10, 2010
GPU Ocelot
What follows are a set of ideas I've been babbling to people over the past few days:
A recent call for papers to contribute to NVIDIA's GPU Computing Gems has prompted the brainstorming of potential uses for GPU Ocelot. It occurs to me that I've not done a post that addresses an important segment of the GPU Ocelot user space: CUDA developers.
While Ocelot makes a good infrastructure for researching GPU architecture, programming models, compiler transformations, and operating systems, it's also incredibly useful for CUDA application development and performance tuning. Ocelot consists of an implementation of the CUDA Runtime API with three backends for executing CUDA kernels on: a full-featured PTX emulator with instrumentation, an efficient translator to multicore CPU, and a CUDA-capable GPU. I'll be focusing on the capabilities enabled by Ocelot's PTX emulator for most of this post.
PTX is the virtual instruction set that the CUDA compiler targets. Ocelot includes an instruction-by-instruction emulation of PTX kernels in a manner that is faithful to the PTX execution model and very similar to how GPUs might execute the kernel. Since Ocelot explicitly computes the state of a PTX kernel for every instruction and every thread, detailed instrumentation and analysis is possible. Here are some of the features that greatly assist in developing CUDA applications and tuning them for efficient execution on GPUs.
Ocelot's PTX emulator is capable of checking for out-of-bounds memory accesses. Without Ocelot, your application might simply seg-fault on the GPU and possibly crash your video driver. There aren't really any tools currently available to help you find these problems, and padding added to memory allocations by the CUDA driver may conceal problems on the system you test with only to explode on your users whose systems may be different.
Beyond global memory accesses, Ocelot's emulator detects race conditions in shared memory that necessitate use of synchronization as well as deadlocks in which not all threads reach a synchronization point. To achieve maximum performance from the memory system, Ocelot includes a way of determining whether the application is taking advantage of spatial locality of data whose accesses can be coalesced in time. At present, we do not detect bank conflicts in which multiple concurrent threads attempt to access the same port of shared memory; on a GPU, these must be serialized greatly impacting performance. I plan to implement that soon.
Finally, Ocelot supports user-contributed trace generators. You could write, for example, a trace generator that watches a particular location in memory and identifies when that location was updated and by which thread(s). I believe I will write this and then, in a blog post, demonstrate how to extend it.
NVIDIA's CUDA does include an emulation target, but this is implemented completely differently using one host thread per logical CUDA thread. This MIMD approach to kernel execution is terribly inefficient, as most of the application runtime is spent by the OS switching contexts between threads. Moreover, it constitutes a radical departure from the way kernels are executed by GPUs to the extent that CUDA kernels that are invalid for subtle reasons may execute correctly on their emulator but incorrectly on a GPU. Ocelot's PTX emulator presents a more similar execution environment that captures the subtleties of the GPU execution model.
GPU Ocelot is fairly stable as of this writing. It has been validated with over a hundred applications from the CUDA SDK, third party benchmark suites, CUDA-based libraries such as GPU VSIPL and Thrust, and custom CUDA applications. Ocelot has been used to capture performance characteristics of these applications as well as find nuanced bugs in existing CUDA programs. It constitutes a great improvement over NVIDIA's emulation mode CUDA runtime in terms of both accuracy, observability of potential bugs, and emulation performance.
A recent call for papers to contribute to NVIDIA's GPU Computing Gems has prompted the brainstorming of potential uses for GPU Ocelot. It occurs to me that I've not done a post that addresses an important segment of the GPU Ocelot user space: CUDA developers.
While Ocelot makes a good infrastructure for researching GPU architecture, programming models, compiler transformations, and operating systems, it's also incredibly useful for CUDA application development and performance tuning. Ocelot consists of an implementation of the CUDA Runtime API with three backends for executing CUDA kernels on: a full-featured PTX emulator with instrumentation, an efficient translator to multicore CPU, and a CUDA-capable GPU. I'll be focusing on the capabilities enabled by Ocelot's PTX emulator for most of this post.
PTX is the virtual instruction set that the CUDA compiler targets. Ocelot includes an instruction-by-instruction emulation of PTX kernels in a manner that is faithful to the PTX execution model and very similar to how GPUs might execute the kernel. Since Ocelot explicitly computes the state of a PTX kernel for every instruction and every thread, detailed instrumentation and analysis is possible. Here are some of the features that greatly assist in developing CUDA applications and tuning them for efficient execution on GPUs.
Ocelot's PTX emulator is capable of checking for out-of-bounds memory accesses. Without Ocelot, your application might simply seg-fault on the GPU and possibly crash your video driver. There aren't really any tools currently available to help you find these problems, and padding added to memory allocations by the CUDA driver may conceal problems on the system you test with only to explode on your users whose systems may be different.
Beyond global memory accesses, Ocelot's emulator detects race conditions in shared memory that necessitate use of synchronization as well as deadlocks in which not all threads reach a synchronization point. To achieve maximum performance from the memory system, Ocelot includes a way of determining whether the application is taking advantage of spatial locality of data whose accesses can be coalesced in time. At present, we do not detect bank conflicts in which multiple concurrent threads attempt to access the same port of shared memory; on a GPU, these must be serialized greatly impacting performance. I plan to implement that soon.
Finally, Ocelot supports user-contributed trace generators. You could write, for example, a trace generator that watches a particular location in memory and identifies when that location was updated and by which thread(s). I believe I will write this and then, in a blog post, demonstrate how to extend it.
NVIDIA's CUDA does include an emulation target, but this is implemented completely differently using one host thread per logical CUDA thread. This MIMD approach to kernel execution is terribly inefficient, as most of the application runtime is spent by the OS switching contexts between threads. Moreover, it constitutes a radical departure from the way kernels are executed by GPUs to the extent that CUDA kernels that are invalid for subtle reasons may execute correctly on their emulator but incorrectly on a GPU. Ocelot's PTX emulator presents a more similar execution environment that captures the subtleties of the GPU execution model.
GPU Ocelot is fairly stable as of this writing. It has been validated with over a hundred applications from the CUDA SDK, third party benchmark suites, CUDA-based libraries such as GPU VSIPL and Thrust, and custom CUDA applications. Ocelot has been used to capture performance characteristics of these applications as well as find nuanced bugs in existing CUDA programs. It constitutes a great improvement over NVIDIA's emulation mode CUDA runtime in terms of both accuracy, observability of potential bugs, and emulation performance.
Tuesday, February 2, 2010
JSON
Last October, I wrote a JSON parser in C++ that constructs a document object structure. A visitor class provides convenient access to the document object, and a number of tests validate the parser. I've also relaxed the specification to permit strings without quotation marks assuming they meet the same rules as variables in a C-like programming language. Multi-byte encodings aren't as well-tested or covered.
I'm preparing to make it available under a BSD license. Here's a sample usage scenario from the test suite.
I'm preparing to make it available under a BSD license. Here's a sample usage scenario from the test suite.
//
// Example JSON usage
//
try {
std::stringstream ss;
json::Parser parser;
// without quotes, and with weird spacing
ss << "{objects:[{id:1, location : [ 0, 0,0]},{id:2,location:[1.25,0.25,4]}]}";
json::Object *object = parser.parse_object(ss);
json::Visitor visitor(object);
json::Visitor obj0 = visitor["objects"][0];
json::Visitor obj1 = visitor["objects"][1];
if ((int)(obj0["id"]) != 1 || (double)(obj0["location"][0]) != 0) {
if (verbose) {
std::cout << "visitor test 0 - failed for obj0\n";
}
passes = false;
}
if ((int)(obj1["id"]) != 2 || (double)(obj1["location"][0]) != 1.25 ||
(double)(obj1["location"][1]) != 0.25 || (double)(obj1["location"][2]) != 4) {
if (verbose) {
std::cout << "visitor test 0 - failed for obj1\n";
}
passes = false;
}
delete object;
}
catch (common::exception &exp) {
passes = false;
std::cout << "parse failed for visitor test 0\n";
std::cout << exp.message << std::endl;
}
Saturday, January 30, 2010
Turkey Albondigas
Emma and I are making this tonight: Turkey albondigas soup. It is spectacular.
Posted here for posterity.
Posted here for posterity.
Sunday, January 17, 2010
Spring 2010
I'm enrolled in two Computer Science courses: CS 6505 for an unneeded grade, and CS 6520 for fun.
In CS6505 on Friday, I was asked to show the rationals are countable. Having seen this problem before, I quickly mapped the rationals onto discrete points in a 2D plane and, while waving hands, showed how they could be counted by spiralling outward from the origin. "There are different classes of infinity," I struggled to explain. The three gentlemen I was sitting with were not necessarily convinced I had done any math or that my explanation was adequate, so I cast about for a better method.
Here it is. Recall that N is the set of natural numbers: {1, 2, 3, ..}, integers are the set Z = {.., -2, -1, 0, 1, 2, ..}, and the rational numbers are numbers that are the ratio of an integer to a natural number. A set is countable iff there exists a mapping to the natural numbers.
Finite sets are of course countable, but showing that infinite sets are countable requires a bit more thought. The integers, for example, may be mapped to natural numbers as follows: let "0" be integer number 1, +1 be integer number 2, -1 be integer number 3, +2 be integer number 4, -2 be integer number 5, and so on. Easy.
Now for the rationals. Consider an integer a represented by the bits (a0 a1 a2 .. an), where a0 is 0 if a is positive and 1 if a is negative, while bits (a1 a2 .. an) denote the absolute value of a. Assume b is an n-bit natural number formed by bits (b1 b2 .. bn). The pair (a, b) represents some rational number. We may now form a string from the bit representation of (a, b) as follows:
(1 a0 a1 b1 a2 b2 a3 b3 .. an bn)
This binary string maps to a unique natural number. Moreover, we see that the set ZxN is a superset of the rationals (-10/5 and -2/1 are the same rational number but distinct in the superset ZxN). Because each element of this superset maps to a unique natural number, it is countable, and therefore the rationals are countable. qed.
My personal take-aways from this experience: (1) writing things down like this rather than drawing visual aids and pointing seems to make people more comfortable, and (2) trying to show something in two slightly different ways is a good exercise.
In CS6505 on Friday, I was asked to show the rationals are countable. Having seen this problem before, I quickly mapped the rationals onto discrete points in a 2D plane and, while waving hands, showed how they could be counted by spiralling outward from the origin. "There are different classes of infinity," I struggled to explain. The three gentlemen I was sitting with were not necessarily convinced I had done any math or that my explanation was adequate, so I cast about for a better method.
Here it is. Recall that N is the set of natural numbers: {1, 2, 3, ..}, integers are the set Z = {.., -2, -1, 0, 1, 2, ..}, and the rational numbers are numbers that are the ratio of an integer to a natural number. A set is countable iff there exists a mapping to the natural numbers.
Finite sets are of course countable, but showing that infinite sets are countable requires a bit more thought. The integers, for example, may be mapped to natural numbers as follows: let "0" be integer number 1, +1 be integer number 2, -1 be integer number 3, +2 be integer number 4, -2 be integer number 5, and so on. Easy.
Now for the rationals. Consider an integer a represented by the bits (a0 a1 a2 .. an), where a0 is 0 if a is positive and 1 if a is negative, while bits (a1 a2 .. an) denote the absolute value of a. Assume b is an n-bit natural number formed by bits (b1 b2 .. bn). The pair (a, b) represents some rational number. We may now form a string from the bit representation of (a, b) as follows:
(1 a0 a1 b1 a2 b2 a3 b3 .. an bn)
This binary string maps to a unique natural number. Moreover, we see that the set ZxN is a superset of the rationals (-10/5 and -2/1 are the same rational number but distinct in the superset ZxN). Because each element of this superset maps to a unique natural number, it is countable, and therefore the rationals are countable. qed.
My personal take-aways from this experience: (1) writing things down like this rather than drawing visual aids and pointing seems to make people more comfortable, and (2) trying to show something in two slightly different ways is a good exercise.
Subscribe to:
Comments (Atom)